{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/pics/20211030/20211030569.png', '推荐 SAP无峰 的文章《SAP小技巧 双LOOP循环的性能优化》','https://www.easysap.com/article-415.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
点击此处--->
 群内免费提供SAP练习系统(在群公告中)
群内免费提供SAP练习系统(在群公告中)
加入QQ群:457200227(SAP S4 HANA技术交流) 群内免费提供SAP练习系统(在群公告中)
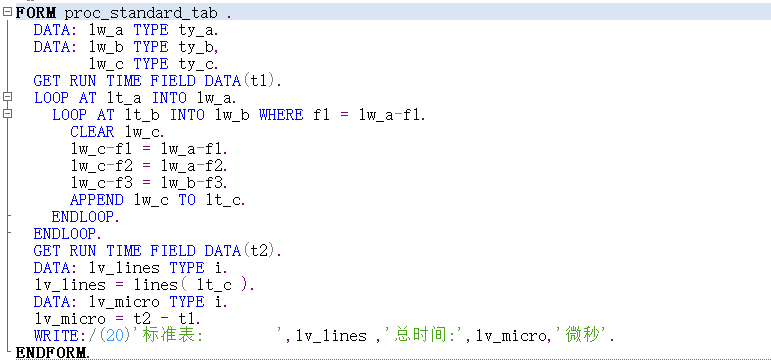
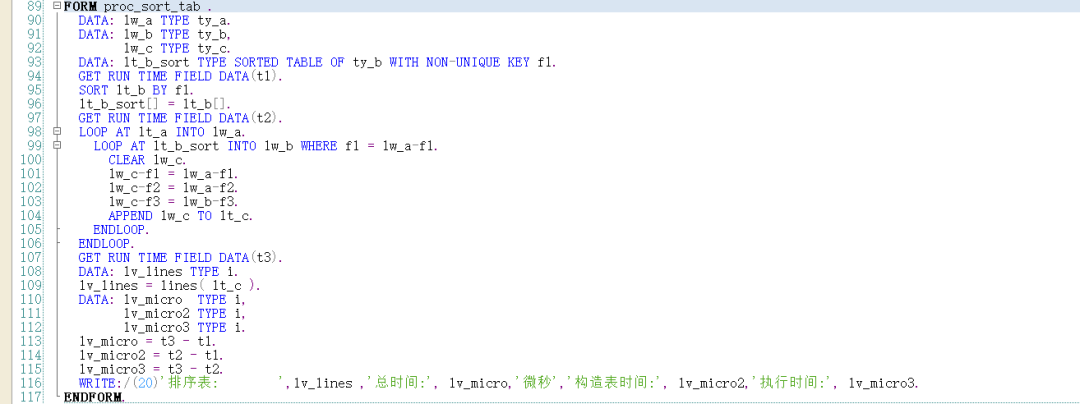
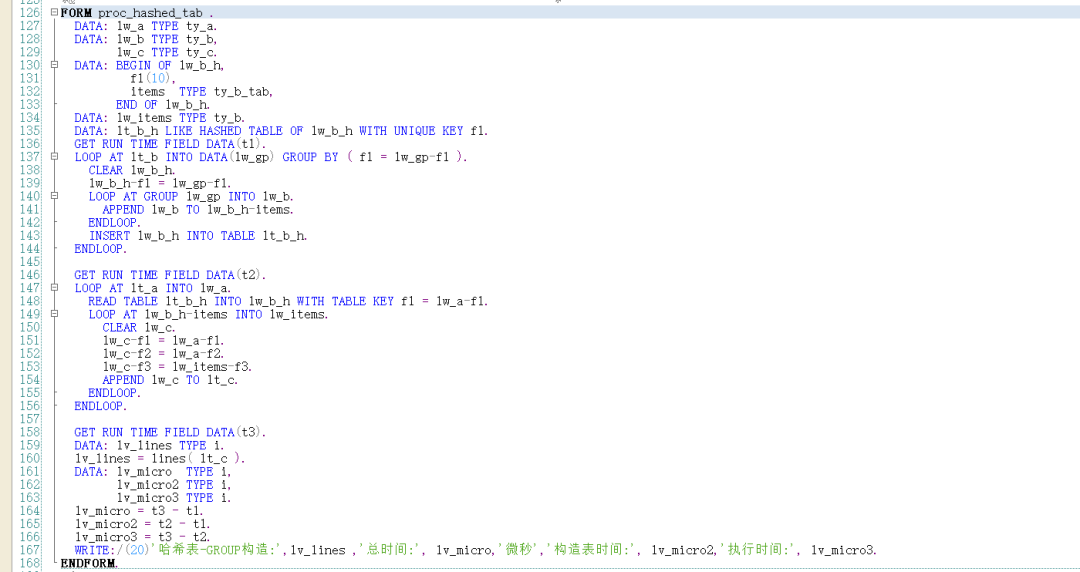
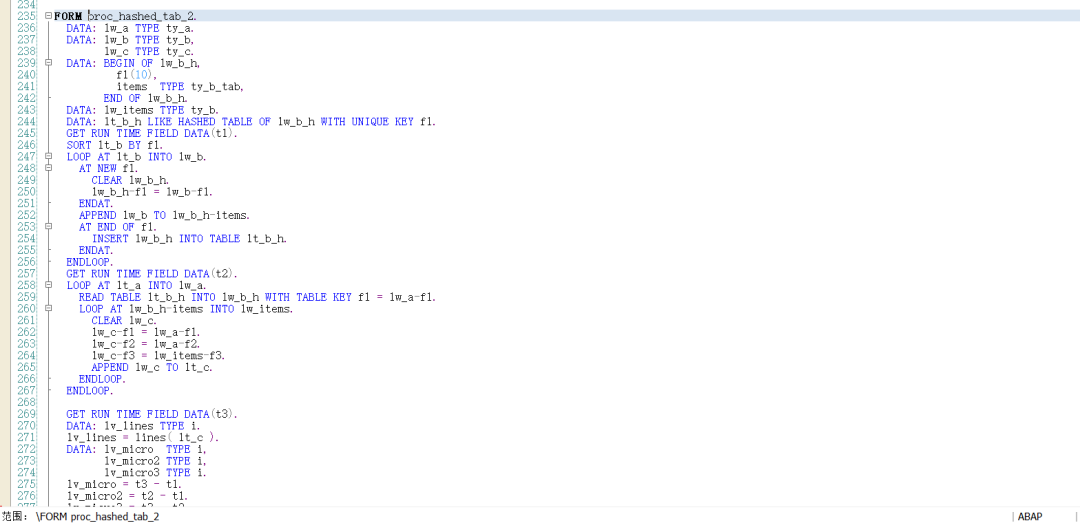
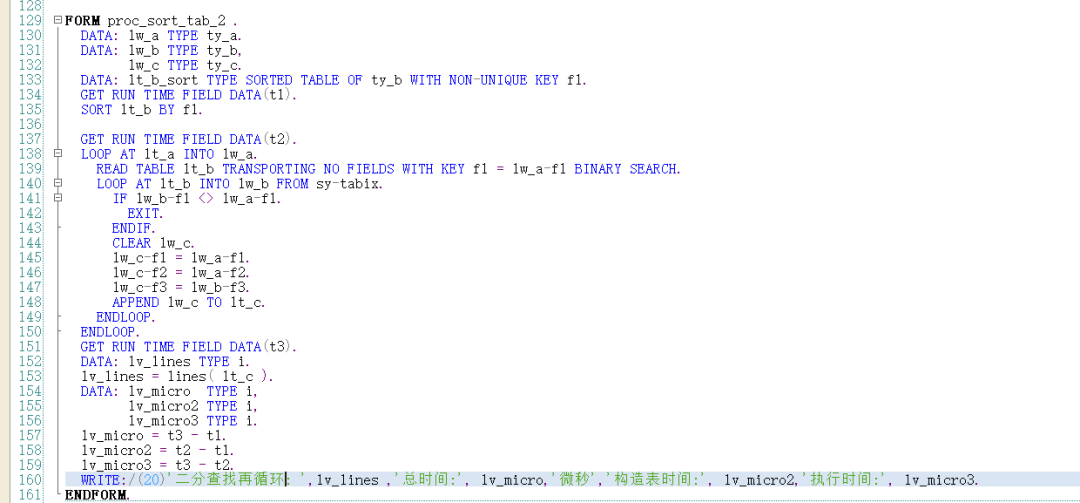
内表A数据重复. 内表A数据不重复 标准内表循环 无需对数据执行任何加工. 逻辑最简单, 但是性能最差. 排序表 需要定义一个排序表,通过赋值语句构造排序表,逻辑较简单,性能较好. 嵌套哈希表 需要构造一个哈希嵌套表,可以通过 GROUP BY 语句构造, 也可以用AT NEW 构造. 逻辑比较复杂, 性能较好 (通过AT NEW 构造比通过GROUP BY 语句构造性能更好 ),但是构造耗时较长. 排序表按INDEX 优化 该方式需要对两个内表都排序, 性能最好, 代码逻辑有点复杂. 并且有使用限制, LT_A-F1内容不能重复(如果内表LT_A 中的F1 内容重复. 则后面的行无法获取数据 ). 使用时请务必确保LT_A 内容不重复. 如下图: 如果LT_A 内容重复. 则INDEX 优化的方式最终获取的内容就不正确了. 二分查找后再循环 对内表LT_B 排序. 代码复杂度低, 性能更好. 建议采用此方式. 需要注意:关键字比较不同之后退出子循环. 约定 如果你对这篇文章感兴趣,请帮忙点赞,在看,分享. (如果你真的喜欢这篇文章,请记得回来打个赏,作为支持我继续下去的动力,这是一个正反馈过程. 越多的人打赏,作者越有动力分享,读者就能享受更多的福利.毕竟打赏的金额富不了我,穷不了你,却能支持这个公众号长久发文.) 公众号 : syjf1976_abap ABAP开发技巧 微信号 : 392077 公众号主群加入受限, 请扫码加入副群后,向管理员申请加入主群