{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','/pics/20211030/20211030557.png', '推荐 SAP无峰 的文章《SAP-ABAP性能优化之构建嵌套结构的哈希表》','https://www.easysap.com/article-414.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
点击此处--->
 群内免费提供SAP练习系统(在群公告中)
群内免费提供SAP练习系统(在群公告中)
加入QQ群:457200227(SAP S4 HANA技术交流) 群内免费提供SAP练习系统(在群公告中)
编者按:
本文的内容是程序性能优化的一种方式. 使用READ TABLE <哈希表> 取代READ TABLE <标准内表>或LOOP AT WHERE <标准内表> .后面的语句即使通过二分法优化读取, 性能还是低于或远低于 read table <哈希表>. 强烈建议所有的开发人员在代码中把需要用READ TABLE 语句访问的内表哈希化. 这样可以获取更好的程序性能.
在取代LOOP AT WHERE <标准内表> 语句时, 需要把<标准内表>中的内容构造一个嵌套的哈希内表.
构造嵌套哈希表的时候.可以使用新语法loop at .. group by .比较简洁易懂. 但是如果内表行数量比较大时. 还是建议使用loop . at new . 方式去构造. 这样性能更好. 只是需要注意at new 语法使用的一些特点: 排序,前面的字段等.
原正文:
工作中我们需要避免LOOP中嵌套LOOP WHERE的写法;这种时候可以尝试构建嵌套结构的哈希表来提升性能。
首先我们看一下使用这种方式的效果,我在系统中尝试了几笔百万级别的数据处理:
本文即将介绍的方式处理了大概4秒( 注: 系统不是S/4 HANA ,不在HANA上 )

而使用LOOP嵌套LOOP WHERE的写法,直接超时...3000秒都没跑出来

接下来我们做一个DEMO来看一下实现方式:
假设一个相对复杂但比较常见的业务场景;
A内表代表总需求: 字段为单据号,单据行项目号,需求数量
可以理解为我们想生产某种产品,需要几个零件


B内表代表总供给: 字段为单据号,单据行项目号,到货日期,到货数量
可以理解为需求的零件采购到货的日期和数量
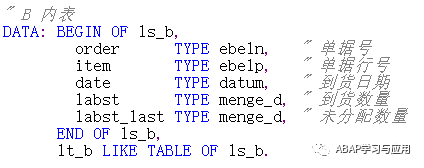
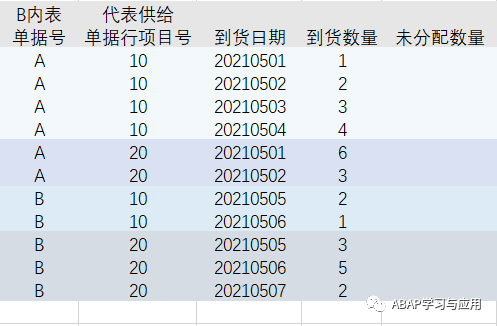
业务逻辑是: 根据到货日期排序,到货日期早的先去满足A内表的需求,允许部分满足,分配完成后记录一下未分配数量,且A内表需记录需求满足后的剩余需求数量
看一下预期的结果,正确的结果应该是:
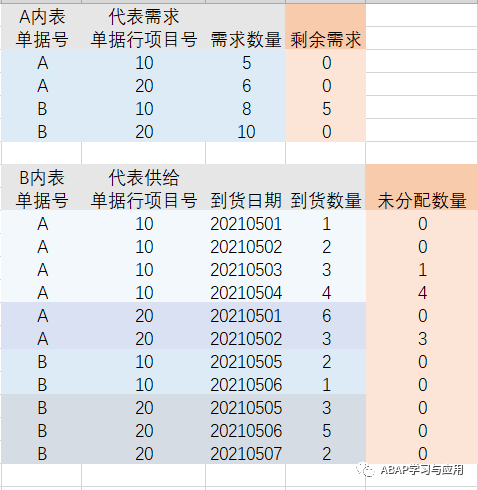
这种模型当数据量很大时应该如何处理才能使得性能最佳呢?
代码实现:
1.声明 key->item[ ] 模式的嵌套哈希表:
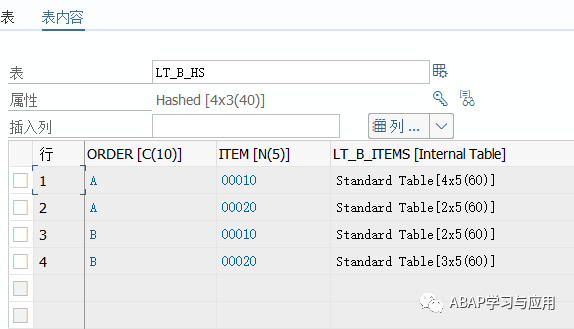
 2.组织数据,遍历内表lt_b,构建出order item对应lt_b_items[ ]的哈希表 lt_b_hs (同样可以使用老语法AT NEW AT END OF,GROUP BY语法在使 用时无需注意内表的字段顺序,且无需排序):
2.组织数据,遍历内表lt_b,构建出order item对应lt_b_items[ ]的哈希表 lt_b_hs (同样可以使用老语法AT NEW AT END OF,GROUP BY语法在使 用时无需注意内表的字段顺序,且无需排序):

debug跟到哈希表lt_b_hs的数据:
3.处理数据,遍历需求内表lt_a,读lt_b_hs,再遍历每一行的lt_b_items[ ]写 处理逻辑:

lt_a的最终结果:
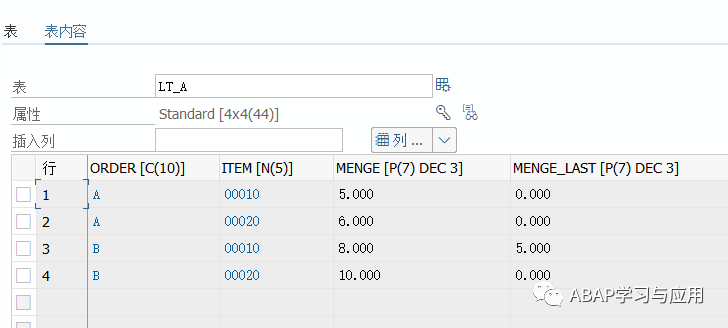
主要介绍的思想就是构建出 key->items[ ]的嵌套哈希结构,通过唯一主键读取到对应的内表直接遍历,这样操作对性能的优化是最佳的;本文的分配逻辑就是模拟一个业务场景来方便理解应该如何具体使用。